The Job is to limit the request
Poorly written by Jovan Lanutan on 2023-08-28T00:00:00.000ZWhen I worked as a junior full-stack web developer, one of my tasks was to build a website and a system that adds content to it. Both were made using (both written in Vue). You can think of the system as a simple content management tool. My boss wanted the website’s content to update automatically based on data from external APIs we were using. I managed to do this, but at first, I set it up on the client side in a way that wasn’t very efficient.
The Problem: API Rate Limits
The big problem was the API rate limits. Like most APIs, the services we used only allowed a certain number of requests per month. For example, if an API allows 500 requests a month, going over that limit causes errors and blocks access. Even our own server had limits to protect our system. Now, imagine if 500 people visited the website in a single day, and every page refresh counted as a request—that monthly limit would be used up in just one day.
First Try: Moving to the Server
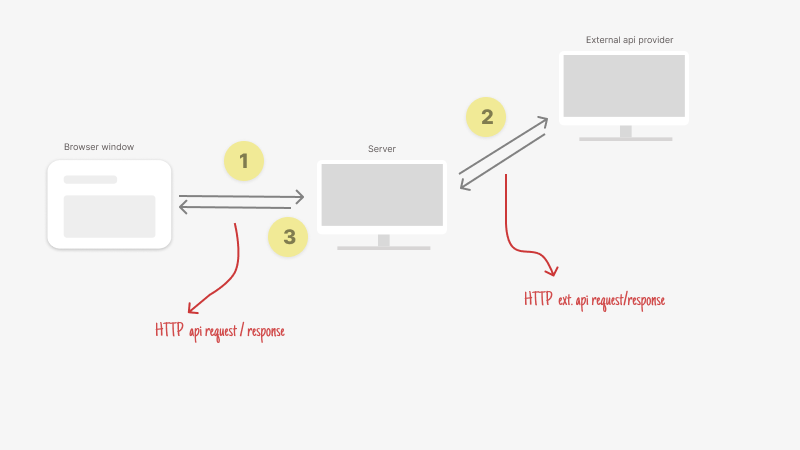 A visualization of request & response cycle with external API services
A visualization of request & response cycle with external API services
To fix this, I moved the code to the server. This meant the server would fetch data from the APIs and then send it to the client (the website). But the problem didn’t go away—every request to the server still made a new API call, which quickly used up our allowed requests.
Learning About Caching
I started looking for solutions and learned about caching. Caching is like saving information temporarily so you can use it again without needing to fetch it repeatedly. It’s like writing down your favorite recipe and keeping it handy instead of opening a cookbook every time. After some research, I found Redis, a tool designed for caching. I talked to my team and decided it would be a good solution.
The Solution: Redis Caching
I used Redis to store API responses and added logic to only fetch new data from the APIs every six hours. This meant we only made four API requests a day, or about 124 requests a month—well under the 500-request limit. Here’s how it worked: when the website asked the server for data, the server first checked Redis. If the data was there, it sent it to the website without making a new API call.